The CSAT Mirage: Why your CX Metrics are Lying about your AI’s Success
Written by: Manya Singh
Last updated: Jul 27, 2026
10 min read

In the rapidly evolving landscape of customer support, a silent crisis is brewing. As companies rush to deploy AI agents, they are still reaching for the same yardsticks they used for human call centres in 2010. But trying to measure a sophisticated AI agent with CSAT is like trying to measure the speed of a jet engine with a stopwatch. It's not just outdated; it's fundamentally deceptive.
The "Inconvenient Truth," as recently highlighted by industry thinkers, is that our most beloved metrics are becoming the biggest obstacles to true AI progress.
Here is why the traditional CX measurement framework is failing the AI era and what we need to build instead.
For decades, Customer Satisfaction (CSAT) has been the North Star of support. It's simple, it's universal, and it's deeply flawed when applied to AI.
The primary issue is Response Bias. CSAT relies on a customer's willingness to fill out a survey. Usually, only the delighted or the enraged respond. For an AI agent handling thousands of micro-interactions, a 5% response rate provides a skewed, "vocal minority" view that ignores the silent 95%.
But there's a deeper, more structural problem.
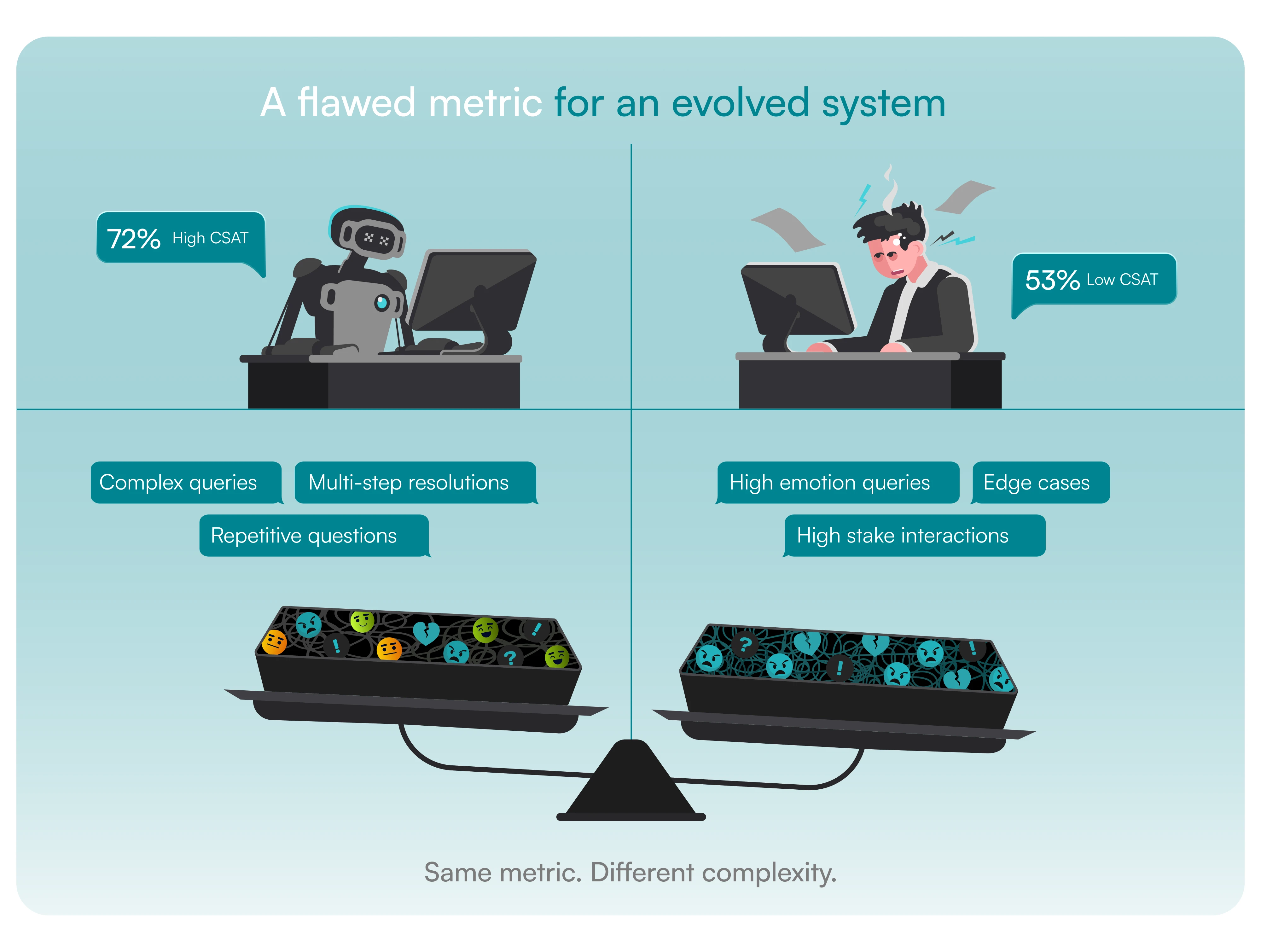
When you deploy an AI agent, it is often first applied to the "low hanging fruit" like password resets, "where is my order" queries, and basic FAQs. These are high-success, low-friction interactions, so naturally, the AI's CSAT appears strong. But that is only part of the picture.
Well-designed AI systems are fully capable of handling complex, high-friction workflows; from refund processing and policy enforcement to multi-step issue resolution. In practice, many of these interactions are already being handled end-to-end by AI. However, the distribution is rarely even.
Human agents still see a disproportionate share of the most escalated, emotionally charged, or edge-case scenarios, while AI continues to process a high-volume of lower-friction interactions alongside an increasing share of complex ones. This creates a distorted comparison.
Human CSAT drops because they are consistently exposed to the hardest situations, while AI CSAT remains elevated due to a blended mix of simple and successfully resolved complex tasks. If you look at these scores in isolation, it can appear as though the AI is outperforming the human team.
But this is not a reflection of capability. It is a reflection of how work is distributed and how outcomes are measured. What CSAT ends up capturing is not how intelligent the system is, but which parts of the problem each system was allowed to solve.
If CSAT is the North Star, "deflection" is often treated as the ultimate win. Deflection, simply put, measures how many customers were kept away from human agents. But, deflection is a misleading metric because it tracks avoidance, not resolution. Think about what "deflected" really includes.
A customer who gets frustrated by a bot and closes the window is "deflected." A customer who gives up and goes to a competitor is "deflected." In many legacy systems, any session that doesn't end in a human transfer is marked as a win. This creates a "Ghost CX" economy, a world where the dashboard says you saved $100k in labour, but your brand equity is quietly bleeding out because problems aren't actually being solved; they're just being silenced.
True AI capability isn't about how many people you kept away from your human team; it's about how many people never needed to come back.
Resolution, Not Deflection (The AR% Shift)
Effort, Not Speed (Rethinking AHT)
The "Effortless" Index (CES as a Core Signal)
Reasoning Quality & Hallucination Rates
The biggest failure of CSAT is that it's a trailing indicator. By the time you see a dip in your monthly CSAT, the damage to your reputation is already done.
AI allows us to use leading indicators. We can now use Predictive CSAT, where an AI model analyses the sentiment, tone, and resolution of an ongoing chat and predicts the satisfaction score before the user even closes the tab. If the "Predicted CSAT" is low, the system can autonomously escalate the ticket to a human lead in real-time.
This isn't just measuring the experience; it's saving it.
Recent research suggests that the best agents aren't "Empathisers" (who just apologise); they are "Controllers." They take charge, tell the customer what needs to happen, and execute it.
In the AI world, we don't need bots that are "polite but useless." We need agents that are "authoritative and effective." When we measure AI, we should look for "Resolution Precision." Does the AI accurately identify the intent (e.g., "This isn't just a delivery question; it's a damaged goods claim") and move straight to the solution?
The transition from human-led support to AI-native support is the biggest shift in CX history. We cannot navigate this new world with a map from the old one.
If your board is still asking for "Bot Deflection" and "Post-Chat CSAT," you are measuring the shadow of the problem, not the substance of the solution. The brands that win in 2026 and beyond will be the ones that stop asking "Are our customers happy?" and start asking "Are their problems actually gone?"
It's time to retire the vanity metrics. It's time to measure the work, not the talk.
If we stop prioritising CSAT, won't our brand tone and human touch suffer?
How is Automated Resolution (AR%) different from a successful Session in my current dashboard?
If AI takes the easy tickets and human CSAT drops, how do we fairly evaluate our human team?
TL;DR
Traditional CX metrics like CSAT and deflection don't accurately measure AI performance because they focus on customer sentiment or avoided interactions rather than successful outcomes.
A high CSAT score doesn't necessarily mean AI is effective. It often reflects the types of queries AI handles, while more complex and emotionally charged issues are routed elsewhere.
The real measure of conversational AI success is automated resolution, how well it understands intent, executes workflows, and solves customer problems end-to-end.
Enterprises should prioritize metrics such as automated resolution rate, customer effort score, reasoning quality, policy adherence, and predictive satisfaction signals over legacy support KPIs.
As customer support becomes AI-native, the organizations that win will measure AI by the business outcomes it delivers, not by how polite, fast, or "human-like" it sounds.